
The smartest AI is the one that knows your business best

March 25, 2026
While big tech companies compete to create bigger, more powerful, and cheaper models, your real competitive advantage lies in something you already have and are not yet ready to unlock its full potential: your company's private data.
Perhaps you don't remember, but when the first version of ChatGPT burst onto the scene and models began to sound almost like human beings, they operated with static databases that contained very limited and obsolete information. In ChatGPT’s case, at the time of its launch in November 2022, the model did not have information about current events that occurred after the beginning of that same year, and this remained the case for many months.
However, the evolution was dizzying, and solutions like Perplexity, Gemini, or Bing Chat quickly moved to not only be trained with all public information available on the internet, but also rapidly gained the ability to connect and search for real-time updated data, such as daily news or stock market quotes.
Today, artificial intelligence dominates all imaginable public knowledge and can update it at any time through a simple search.
Upon reaching this point, where giants like OpenAI, Google, Anthropic, or Meta devour exactly the same data from the same public network for their models, it is clear that in just a few years, the creation of the model itself will cease to be the major competitive advantage.
It is possible that before long, these systems will become powerful, standardized, and very possibly interchangeable reasoning engines, where other parameters will prevail, such as cost and, why not say it, their values and principles.
Beyond this, for these intelligent tools to reach their maximum value, they need to take a step beyond general public knowledge. The authentic technological revolution lies in their capacity to connect and reason using companies' private data, maintaining that information strictly confidential and without sharing it with third parties at all times.
This view on the standardization of public models and the immense untapped value of corporate information is, in fact, the central premise recently defended by Larry Ellison, Oracle's chairman and chief technology officer, during a much-discussed intervention at the end of 2025.
Ellison explained that the real global change will not come from training new models with the same Internet, but from using techniques that allow the use of companies' private data and enable the model we choose to reason about it. It is this strategic combination that truly makes a difference in the business market, as it is what will genuinely make some companies more competitive than others.
Your challenge is not the model, it's your data##
The next step for companies should be simple. It only seems to require connecting our organization's data to the models, and voilà, we are in business.
But we are not. It is not that simple. Precisely, it is anticipated that throughout 2026, data-related problems will solidify as the main "wall" hindering the progress of artificial intelligence.
Right now, companies operate in environments rich in models with public data, but poor in private data. This directly affects AI initiatives, which struggle to scale because their intelligence is trapped in fragmented silos.
If an AI agent does not have visibility into internal systems (such as an ERP or a CRM), it lacks a complete view and may end up making critical decisions blindly. The other option would be to ignore them and have all companies make decisions based on the same public data but, then, what strategic or differential long-term value would those decisions have?
To understand why data is that "wall," one only needs to analyze its real situation with a few direct questions: Are your data warehouses connected to each other or do they function as silos? Are you capable of crossing the information from your transactional systems with your analytical data? That is, are you capable of making the world of "how you manage your business" (transactional) converge with the world of "how you understand your business" (analytical)?
This fragmentation generates what is known as "Data Debt": the accumulation of inaccurate, obsolete, or poor-quality information that hinders decision-making and increases operational costs. This accumulation causes inefficiencies that will require costly cleaning and correction efforts in the future.
And we are only talking about data fragmentation. Let's take another step: once we manage to unite all the information, can we ensure that this data is of quality?
How to prevent poor data quality##
To solve the problem of data quality, we cannot continue using the tools of the past. Traditional approaches, such as periodic reviews within a data warehouse, have become obsolete. Modern AI systems interact with information in real-time, so old batch methods simply no longer scale.
This evolution demands a change in philosophy: organizations must "shift left." That is, act on data quality at its origin—bringing detection, prevention, and correction closer to the moment data is created—instead of waiting for problems to emerge in later stages.
To achieve this, it is essential to treat quality not as a checklist, but as an operating model. Having a program of this type not only helps avoid the consequences of bad information but also creates a competitive advantage in an era where AI depends on reliable, real-time data.
This model can be put into practice through a series of concrete actions:
Establish strong and adaptive governance
Governance remains the foundation, but it must be dynamic, allowing the alignment of ownership, lineage, metadata, and quality controls with data assets. This ensures that AI applications always know which data they can trust.
Real-time detection and monitoring
Instead of relying on batch reviews, the most advanced organizations use streaming observability and automated anomaly detection. This proactive approach allows teams to intervene before faulty data affects analysis or AI systems.
Automate correction
Manual cleaning can no longer keep pace with current data volumes. AI-assisted remediation—such as automated deduplication or self-healing pipelines—helps resolve problems earlier and with less human intervention.
Validation at the point of entry
Validation must occur before data is consumed. Integrating quality controls into ingestion, APIs, or event streams ensures that incorrect data never reaches production systems.
A scalable and autonomous data platform for the agentic era##
At this point, the conclusion is clear: few companies have an integral solution that allows them, on one hand, to securely create, deploy, and govern agents, and on the other, to implement an efficient and scalable data architecture to break silos and unify information wherever it is.
In the field of artificial intelligence platforms, we have spoken before about Gemini Enterprise, but for the specific case of Data, we are not talking about one particular product but the entirety of Google Cloud Platform as it is, in itself, a data platform. Moreover, we could say that it is the most demanding data management platform with the most extreme cases that exists, since it supports all of Google Cloud's consumer products (Search, YouTube, Maps, etc.) and the artificial intelligence systems they rely on.
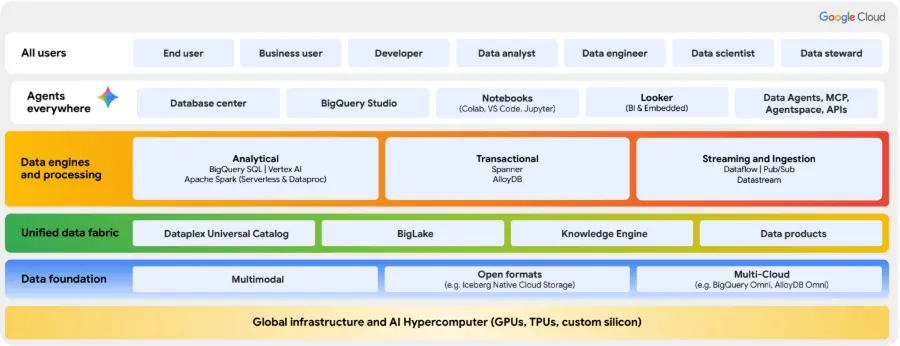
Google Cloud offers us unique strategic flexibility, providing companies with both solutions in the field of artificial intelligence and solutions to operate their data in two complementary ways, depending on their starting point.
On one hand, we can work exclusively on Google Cloud, thus functioning as a native and highly integrated platform, where services such as Dataplex centralize governance, Dataflow automates quality data ingestion, and the combination of BigQuery with AlloyDB or Spanner unifies analysis with real-time operations. What do we achieve with this approach? Maximizing efficiency and performance by consolidating the entire data ecosystem into a single, highly scalable, and cost-optimized environment.
On the other hand, recognizing that most companies operate today in a hybrid environment, Google Cloud can act as a control and analysis plane for a multicloud ecosystem. The key to this strategy lies in BigLake, which catalogs data regardless of whether it is in Google Cloud, AWS, or Azure, and in BigQuery Omni, the engine that executes queries directly where the data resides. This allows for governing and analyzing information in other clouds without needing to move it, eliminating transfer costs and drastically reducing latency.
Google Cloud offers the best of both worlds: the power of a unified solution and the intelligence to manage a distributed data universe. Whether centralizing operations or extending its governance to other clouds, the architecture provides a solid and flexible foundation for building a data strategy ready for the future of AI.
However, having these powerful tools is only the first step. The true differentiator lies in the experience needed to design, implement, and optimize these complex architectures, adapting them to the unique needs of each business. At Sngular, we have extensive experience precisely resolving these challenges. If you wish to know more about how to apply these approaches to your particular case and accelerate your path toward profitable AI, we invite you to contact us con nosotros.
Our latest news
Interested in learning more about how we are constantly adapting to the new digital frontier?

Tech Insight
June 25, 2026
Let Gemini Do It: Generative AI for Businesses on Google Cloud

Tech Insight
June 18, 2026
No Data, No AI: Agentic Data Cloud and Data Sovereignty

Tech Insight
June 16, 2026
Generative UI: When AI Architecture Builds the Interface, Not Just the Text

Corporate news
June 4, 2026
Chris Brown Named to Fast Company Executive Board for Leadership in AI, Data, and Digital Engineering