
La IA más inteligente es la que mejor conoce tu negocio

25 de marzo de 2026
Mientras las grandes tecnológicas compiten por crear modelos más grandes, potentes y baratos, tu verdadera ventaja competitiva está en algo que ya tienes y que todavía no estás preparado para sacarle todo su potencial: Los datos privados de tu empresa.
Quizá ya no te acuerdes, pero cuando irrumpió la primera versión de ChatGPT en escena y los modelos comenzaron a sonar casi como seres humanos, operaban con bases de datos estáticas que contenían información muy limitada y obsoleta. En el propio caso de ChatGPT, en el momento de su lanzamiento en noviembre de 2022, el modelo no tenía información sobre eventos actuales ocurridos después de principios de ese mismo año, y así se mantuvo muchos meses.
Sin embargo, la evolución fue vertiginosa: soluciones como Perplexity, Gemini o Bing Chat no tardaron mucho en ser entrenados con toda la información pública disponible en internet, además de contar rápidamente con la capacidad de conectarse y buscar datos actualizados en tiempo real, como las noticias del día o las cotizaciones de la bolsa.
Hoy en día, la inteligencia artificial domina todo el conocimiento público imaginable y puede actualizarlo en cualquier momento a través de una simple búsqueda.
Al llegar a este punto, donde gigantes como OpenAI, Google , Anthropic o Meta devoran para sus modelos exactamente los mismos datos de la misma red pública, se vislumbra que en tan solo unos años la creación del modelo en sí misma va a dejar de ser la gran ventaja competitiva.
Es probable que no dentro de mucho, estos sistemas se conviertan en potentes motores de razonamiento estandarizados y, muy posiblemente, intercambiables, donde lo que primará serán otros parámetros como su coste. E incluso por qué no decirlo, sus valores y principios.
Más allá de esto, para que estas herramientas inteligentes alcancen su valor máximo, necesitan dar un paso más allá del conocimiento público general. La auténtica revolución tecnológica radica en su capacidad para conectarse y razonar utilizando los datos privados de las empresas, manteniendo en todo momento esa información estrictamente confidencial y sin compartirla con terceros.
Esta visión sobre la estandarización de los modelos públicos y el inmenso valor inexplorado de la información corporativa es, de hecho, la premisa central que defendió hace no mucho Larry Ellison, presidente y director de tecnología de Oracle durante una comentada intervención a finales de 2025.
Ellison explicó que el verdadero cambio mundial no provendrá de entrenar nuevos modelos con la misma Internet, sino de utilizar técnicas que permitan utilizar los datos privados de las compañías y permitir que el modelo que elijamos razone sobre ellos. Es esta combinación estratégica la que verdaderamente viene a marcar la diferencia en el mercado empresarial, ya que es lo que realmente hará más competitivas a unas empresas que otras.
Tu reto no es el modelo, son tus datos
El siguiente paso para las empresas debería ser sencillo. Lo único que parece faltar es conectar los datos de nuestra organización a los modelos y, ¡voilá!, ya estamos en marcha.
Pero no. No es tan sencillo. Precisamente, se prevé que a lo largo de este 2026 los problemas relacionados con los datos se consoliden como el principal “muro” que detiene el progreso de la inteligencia artificial.
Ahora mismo, las empresas operan en entornos ricos en modelos con datos públicos, pero pobres en datos privados. Esto afecta directamente a las iniciativas de IA, que encuentran dificultades para escalar porque su inteligencia está atrapada en silos fragmentados.
Si un agente de IA no tiene visibilidad sobre los sistemas internos (como un ERP o un CRM), carece de una visión completa y puede terminar tomando decisiones críticas a ciegas. La otra opción sería obviarlos y que todas las empresas tomen decisiones basándose en los mismos datos públicos pero, entonces, ¿qué valor estratégico o diferencial tendrían esas decisiones a largo plazo?
Para entender por qué los datos son ese “muro”, basta con analizar su situación real con unas preguntas directas: ¿Están tus almacenes de datos conectados entre sí o funcionan como silos? ¿Eres capaz de cruzar la información de tus sistemas transaccionales con tus datos analíticos? O sea, ¿eres capaz de hacer converger el mundo de “cómo gestionas tu negocio” (transaccional) con el de “cómo entiendes tu negocio” (analítico)?
Esta fragmentación genera lo que se conoce como "Deuda de Datos": la acumulación de información inexacta, obsoleta o de mala calidad que dificulta la toma de decisiones y aumenta los costes operativos. Dicha acumulación provoca ineficiencias que requerirán costosos esfuerzos de limpieza y corrección en el futuro.
Y estamos hablando solo de la fragmentación de los datos. Demos un paso más: una vez que conseguimos unir toda la información, ¿podemos asegurar que esos datos son de calidad?
Cómo prevenir la mala calidad de los datos
Para solucionar el problema de la calidad de los datos, no podemos seguir usando las herramientas del pasado. Los enfoques tradicionales, como las revisiones periódicas dentro de un almacén de datos, se han quedado obsoletos. Los sistemas de IA modernos interactúan con la información en tiempo real, por lo que los antiguos métodos por lotes (batch) simplemente ya no escalan.
Esta evolución exige un cambio de filosofía: las organizaciones deben "desplazarse a la izquierda" (shift left). Es decir, actuar sobre la calidad de los datos en su origen —acercando la detección, prevención y corrección al momento en que se crean— en lugar de esperar a que los problemas surjan en etapas posteriores.
Para lograrlo, es fundamental tratar la calidad como un modelo operativo, en lugar de como una lista de verificación. Contar con un programa de este tipo ayuda a evitar las consecuencias de la mala información y crea una ventaja competitiva en una era donde la IA depende de datos fiables en tiempo real.
Este modelo se puede poner en práctica a través de una serie de acciones concretas:
Establecer una gobernanza fuerte y adaptativa
La gobernanza sigue siendo la base, pero debe ser dinámica, permitiendo alinear la propiedad, el linaje, los metadatos y los controles de calidad con los activos de datos. Esto garantiza que las aplicaciones de IA siempre sepan en qué datos pueden confiar.
Detección y monitorización en tiempo real
En lugar de depender de revisiones por lotes, las organizaciones más avanzadas utilizan observabilidad en streaming y detección automatizada de anomalías. Este enfoque proactivo permite a los equipos intervenir antes de que los datos defectuosos afecten a los sistemas de análisis o IA.
Automatizar la corrección
La limpieza manual ya no puede seguir el ritmo de los volúmenes de datos actuales. La remediación asistida por IA —como la deduplicación automatizada o los pipelines de autocuración— ayuda a resolver problemas de forma más temprana y con menor intervención humana.
Validación en el punto de entrada
La validación debe ocurrir antes de que los datos sean consumidos. Integrar controles de calidad en la ingesta, las APIs o los flujos de eventos garantiza que los datos incorrectos nunca lleguen a los sistemas de producción.
Un plataforma de datos escalable y autónoma para la era agéntica
Llegados a este punto, la conclusión es clara: pocas empresas disponen de una solución integral que les permita, por un lado, crear, desplegar y gobernar agentes de forma segura y, por otro, implementar una arquitectura de datos eficiente y escalable para romper los silos y unificar la información allá donde esté.
En el ámbito de las plataformas de inteligencia artificial ya hemos hablado en otras ocasiones de Gemini Enterprise, pero para el caso particular de los Datos no hablamos de un producto en particular si no de Google Cloud Platform al completo, ya que es en sí misma una plataforma de datos. Es más, podríamos decir que es la plataforma de gestión de datos más exigente y con los casos más extremos que existe, ya que da soporte a todos los productos de consumo de Google Cloud (Search, Youtube, Maps, etc.) y a los sistemas de inteligencia artificial en los que se apoyan.
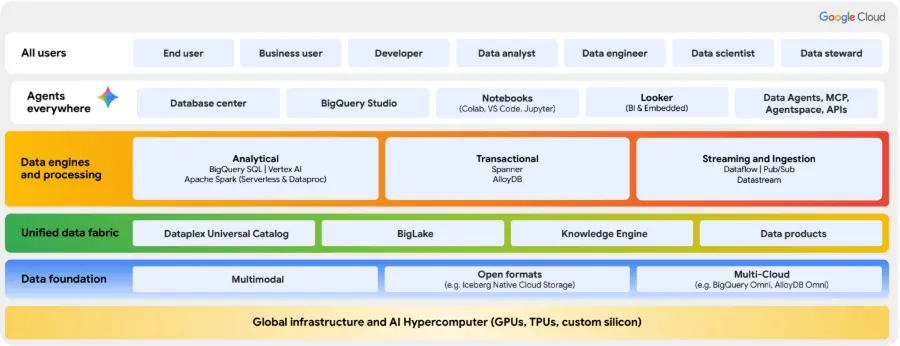
Google Cloud nos ofrece una flexibilidad estratégica única, ofreciendo a las empresas tanto soluciones en el ámbito de la inteligencia artificial como soluciones para operar sus datos de dos maneras complementarias, según sea su punto de partida.
Por un lado, podemos trabajar exclusivamente sobre Google Cloud, funcionando así como una plataforma nativa y altamente integrada, donde servicios como Dataplex centralizan el gobierno, Dataflow automatiza la ingesta de datos de calidad y la combinación de BigQuery con AlloyDB o Spanner unifica el análisis con las operaciones en tiempo real. ¿Qué conseguimos con este enfoque? Maximizar la eficiencia y el rendimiento al consolidar todo el ecosistema de datos en un único entorno altamente escalable y optimizado en costes.
Por otro lado, y reconociendo que la mayoría de las empresas operan hoy en día en un entorno híbrido, Google Cloud puede actuar como un plano de control y análisis para un ecosistema multicloud. La clave de esta estrategia reside en BigLake, que cataloga los datos sin importar si están en Google Cloud, AWS o Azure, y en BigQuery Omni, el motor que ejecuta las consultas directamente donde residen los datos. Esto permite gobernar y analizar información en otras nubes sin necesidad de moverla, eliminando costes de transferencia y reduciendo la latencia de forma drástica.
En esencia, Google Cloud ofrece lo mejor de ambos mundos: la potencia de una solución unificada y la inteligencia para gestionar un universo de datos distribuido. Ya sea centralizando sus operaciones o extendiendo su gobierno a otras nubes, la arquitectura proporciona una base sólida y flexible para construir una estrategia de datos preparada para el futuro de la IA.

Sin embargo, disponer de estas potentes herramientas es solo el primer paso. El verdadero diferenciador reside en la experiencia para diseñar, implementar y optimizar estas arquitecturas complejas, adaptándolas a las necesidades únicas de cada negocio. En Sngular, contamos con larga experiencia resolviendo precisamente estos desafíos. Si quieres saber más sobre cómo aplicar estos enfoques a tu caso particular y acelerar tu camino hacia una IA rentable, te invitamos a contactar con nosotros.
Nuestras últimas novedades
¿Te interesa saber cómo nos adaptamos constantemente a la nueva frontera digital?

Tech Insight
25 de junio de 2026
Que lo haga Gemini: IA generativa para empresas en Google Cloud

Tech Insight
18 de junio de 2026
Sin datos no hay IA: Agentic Data Cloud y la soberanía de la información

Tech Insight
16 de junio de 2026
Generative UI: cuando la IA no solo responde, sino que construye la interfaz

Corporate news
4 de junio de 2026
Chris Brown se une al Consejo Ejecutivo de Fast Company por su liderazgo en IA, datos e ingeniería digital