
Computer Vision & Edge Computing
January 2, 2023
Neural networks and edge computing for automatic license plate detection
How interesting: the standard way to train a computer vision system is similar to the way we teach children. We point to objects and tell the system what they are so it can identify them clearly. We repeat this process until the child (our model in this case) starts to recognize patterns in the information we give them: a cat usually has pointed ears and four legs, a bird has a beak and wings, a car has wheels, doors, and a steering wheel.
This process is known as supervised learning. A system that learns, but doesn’t do so completely by itself. Indeed, a model must be explicitly taught what each object is by assigning it a “label”.
So, once a model receives enough correctly labeled images with the main features of the objects of interest, it can be used for an application. How is this done? Simply by processing an image and collecting the model's output, which is the object detected. As we saw in the previous examples (the cat, the bird, or the car), the system can classify objects thanks to patterns if found in images.
This is what Sngular's Artificial Intelligence] team has done for the creation of an automatic license plate detection system. Specifically, it consists of an Android application implanted into a camera, which is able to detect and read the license plates that appear in the camera's video stream and send the information to a video management system or a server. That is, the system processes an image (or video) as an input, detects the license plates that appear and reads the characters of these plates.
What is a license plate detection system used for? One of the common problems it solves is that it reduces the number of steps required for a driver to enter and exit a parking lot by automating parking management. Another common use case is traffic management, as the system can be used to detect speeding vehicles or to control access to restricted areas of a city.
The ultimate goal of the project is none other than to design an application able to identify the license plates of any vehicle in any scenario, whether it is a car entering a garage, a motorcycle driving in a city center, or a truck on a highway. All of this, without limits as to the number of vehicles or the type of license plate.
Edge computing: processing data in local
But there’s more. License plate recognition is not new, but we created a new way to carry it out. Now, data processing is done on the device itself, which enables us to use a simpler infrastructure and improve privacy. This is what we call edge computing.
The main advantage of using a camera with processing capability is that no additional hardware is needed to configure the system: all we need is a power supply for the camera and a standard internet connection to send the detected license plates. Thanks to this, the system can be deployed in remote areas where internet capacity may be limited and the installation costs are significantly reduced: non-edge computing systems require additional servers to be installed for data processing, which could be especially challenging in less accessible areas.
The technology we used to develop our edge computing system is Bosch's INTEOX platform. One of its main advantages is its flexibility, as it enables developing customer-specific applications or customizing existing ones. Once an application has been developed, the same blocks can be reused to build different applications. This allowed us to quickly create other applications for pedestrian counting and vehicle classification.
How to create a computer vision system
Manuel Renner, Jorge Prudencio, and Javier Pulido, from Sngular, have led this pilot project, which started as a laboratory test of what it could be used for in the near future: traffic flow optimization, parking management, access control, law enforcement, and much more. Many of these applications result in significant social and economic benefits.
First, we developed a proof of concept of a system capable of detecting and reading accurately the license plates from various images. To complete this first phase, we had to find suitable models and adjust them to our needs.
In the second phase, we integrated these models into an Android application running directly on the camera. This required close collaboration between software developers and data scientists to build the first version of the application.
The third phase, which the team is currently working on, consists of optimizing the system in terms of accuracy and speed, with the aim of enabling the camera to read several license plates at once, in real time, and with high precision.
The software runs entirely on the camera, which comes with an Android operating system. Therefore, we used Java and Kotlin to develop an Android application that could be installed easily on the camera.
But the technology used for this type of project varies from system to system. The detection component is usually built using Deep Learning frameworks such as Tensorflow and Computer Vision libraries such as OpenCV, which can be easily implemented in various software architectures. This will depend on the hardware used.
How does it work?
For each received from a camera video stream, a model is run to detect license plates within the iframe mage. If a license plate is detected, its area on the image is extracted and processed to improve definition.
The processed image then is analyzed by a second model that recognizes the characters and generates the license plate in text format. This result, together with a timestamp, can be sent to any video management system or servers for further use.
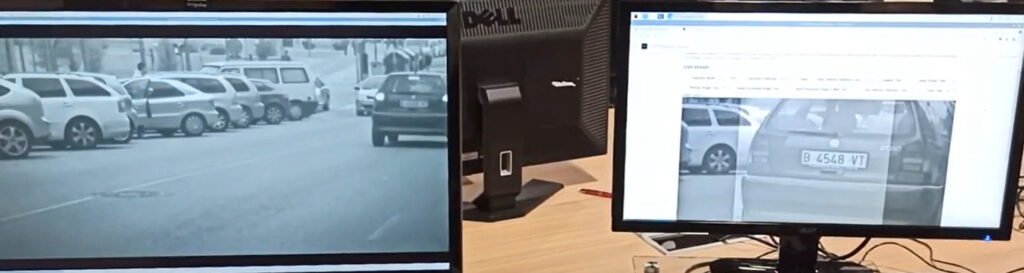
Integration challenge
According to Manuel Renner, the main difficulty in the development of the system was the integration and optimization of the computer vision component of the software. Much of the original development (proof of concept, evaluation, etc.) was done with Python, as it allows faster development and evaluation. Then, it had to be translated into Java/Kotlin so that the models and logic could be implemented into the camera, which proved to be a challenge for the team.
This is precisely how Manuel defines it: a challenge to overcome. But, despite its complexity, all the team members admit that they have learned a lot along the way, which is why it has been a rewarding experience as a whole.
"The team is made up of very skilled people and the fact that we started something new from scratch and got to where we are now is a great achievement"
The technical team counted on engineers, data scientists, and machine learning engineers experienced in computer vision, as well as software developers. In addition, a product owner supervised the project’s development and guided the engineering efforts. Likewise, it is fundamental to understand what potential customers are looking for and to ensure that the system can meet the market’s top needs.
This project is just one example of what we are able to create by combining computer vision and edge computing techniques. Thanks to this combination, computer vision systems are much more accessible, as they don’t require additional processing units. Cameras can be easily installed in any environment and perform a wide variety of tasks such as estimating waiting times in a queue, counting different types of products in a production line, managing traffic flow systems, etc.
Our latest news
Interested in learning more about how we are constantly adapting to the new digital frontier?

Tech Insight
June 25, 2026
Let Gemini Do It: Generative AI for Businesses on Google Cloud

Tech Insight
June 18, 2026
No Data, No AI: Agentic Data Cloud and Data Sovereignty

Tech Insight
June 16, 2026
Generative UI: When AI Architecture Builds the Interface, Not Just the Text

Corporate news
June 4, 2026
Chris Brown Named to Fast Company Executive Board for Leadership in AI, Data, and Digital Engineering