
Clonación de voz: habla por quien quieras

26 de febrero de 2024
En un mundo en el que las máquinas empiezan a eclipsar las capacidades humanas, el concepto de clonación de voz añade un giro apasionante. Imagine las posibilidades: asistentes personales con un toque humano, personajes de videojuegos que suenan inquietantemente auténticos o narradores de libros con la voz de su famoso favorito. No se trata sólo de entretenimiento. La clonación de voz en tiempo real también puede aplicarse para ayudar a personas con enfermedades o discapacidades que afectan a su capacidad de hablar.

Este artículo te adentra en la mecánica de la clonación de voz en tiempo real, descifrando sus complejidades de forma sencilla. ¿Qué hace que esta aventura sea aún más interesante? Nuestro objetivo no es otro que nuestra colega de SNGULAR, líder del equipo y experta en IA, Nerea Luis. Puede que estés acostumbrado a oír a Nerea hablar de robótica e IA en programas como Orbita Laika y Cuerpos Especiales. Hoy clonaremos la voz de Nerea y la oirás hablar de algo diferente: recitará el principio de El Señor de los Anillos.
Clonación de voz vs Text-To-Speech – Coqui-AI
La clonación de voz es el proceso en el que se utiliza un ordenador para generar el habla de una persona real, generando una réplica de su voz específica y única mediante inteligencia artificial (IA).
Los sistemas de texto a voz (TTS), pueden tomar el lenguaje escrito y transformarlo en comunicación hablada, pero no deben confundirse con la clonación de voz. Los sistemas TTS son mucho más limitados en cuanto a los resultados que producen en comparación con la tecnología de clonación de voz, que en realidad es más un proceso personalizado.
Una herramienta muy popular para la clonación de voces es coqui-ai TTS. Coqui es una startup que ofrecía tecnología de voz de código abierto. Ya no existe, pero su repositorio de github para clonación de voces todavía tiene mucho que ofrecer. Otro repositorio interesante es All Talk TTS, que se basa en la tecnología de Coqui pero ofrece una interfaz de usuario fácil de usar. Sin embargo, en este artículo utilizaremos el repositorio de Coqui para nuestros experimentos.
Cómo funciona
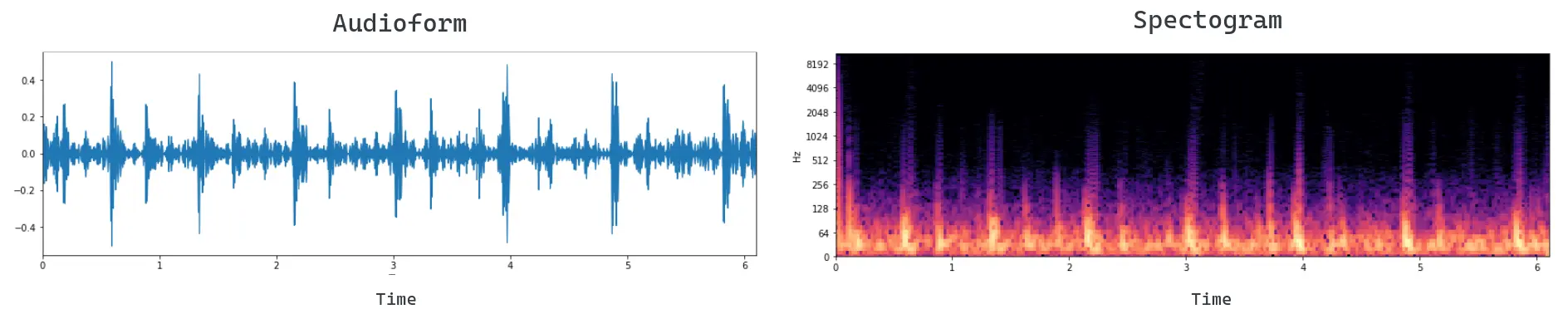 Figura 1: visualización de una señal de audio en Audioform (izquierda) y espectrograma (derecha).
Figura 1: visualización de una señal de audio en Audioform (izquierda) y espectrograma (derecha).
El sistema típico de clonación de voz consta de cuatro bloques principales, cuatro modelos que funcionan juntos para permitirle clonar la voz deseada (véase la Figura 2).
- Text-to-Mel encoder: convierte el texto que quieres que lea tu locutor en un espectrograma mel, que es una forma habitual de representar el habla. Puedes obtener más información sobre qué son los espectrogramas mel en este artículo de Medium.
- Vocoder o codificador de voz: red neuronal que toma este espectrograma mel y lo convierte en una forma de onda. En otras palabras, el Vocoder convierte el espectrograma en una señal de audio (véase la Figura 1).
- Codificador del locutor: red neuronal que toma una breve muestra de audio del locutor objetivo y la codifica en un vector de longitud fija que representa las características únicas de la voz del locutor. Este vector se utiliza para condicionar el vocoder durante la síntesis del habla, permitiendo que el modelo genere un habla que se asemeje al hablante de referencia.
- Sintetizador en tiempo real: genera el archivo de audio, que consiste en la voz del locutor de referencia pronunciando el texto deseado.
En la Figura 2 se puede ver un esquema que muestra el flujo de datos a través de cada bloque mencionado dentro de un sistema genérico de clonación de voz. Coqui ofrece múltiples opciones de modelos TTS. Puede jugar con ellas (y con muchas otras) en el hugging space de Coqui, y chequear los detalles en su documentación.
Para nuestros ejemplos usaremos el modelo XTTS v2, un modelo de generación de voz que te permite clonar voces en diferentes idiomas y que da muy buenos resultados con sólo un clip de audio de muestra de 6 segundos de tu altavoz de referencia. Simplemente mostrando al modelo una o pocas muestras (sin afinarlo) puedes obtener audios bastante realistas. Si es necesario, también te permite realizar ajustes.
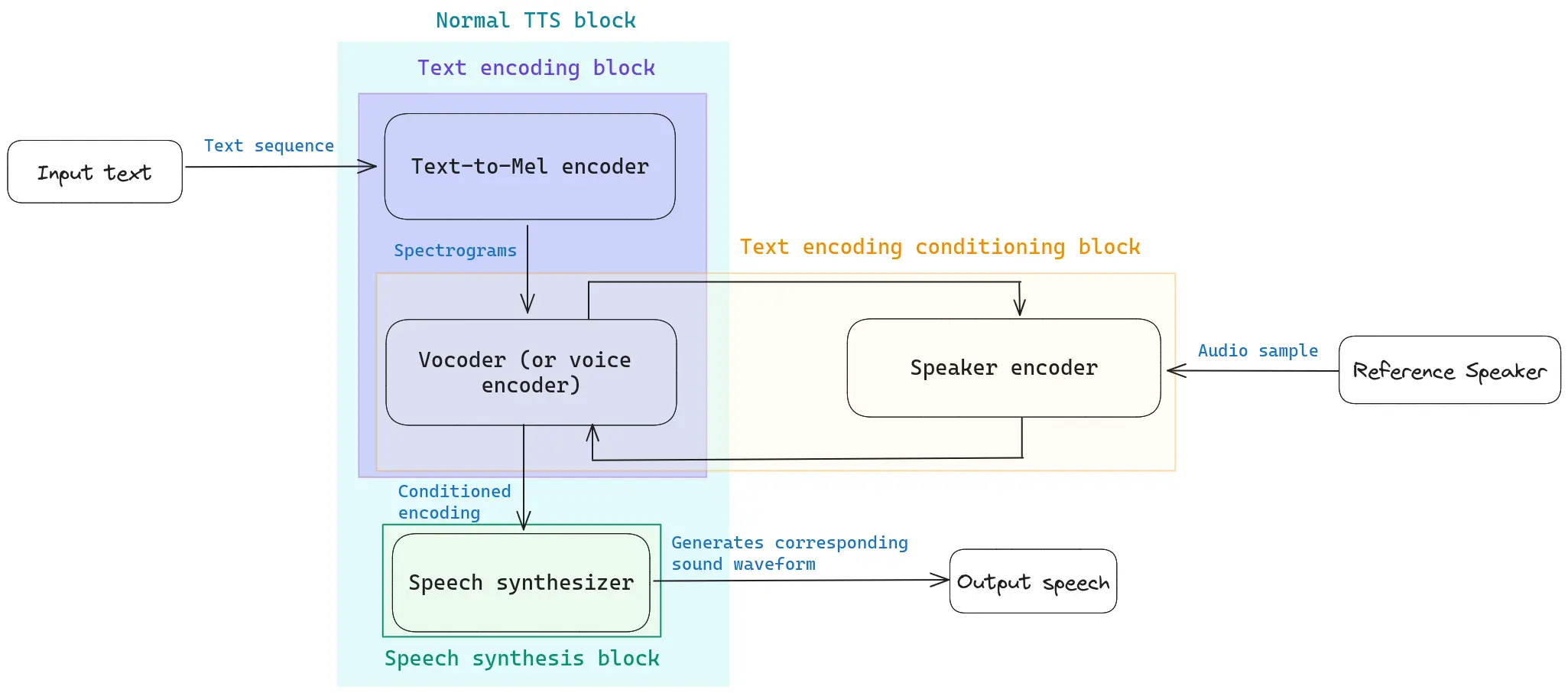 Figura 2: Resumen esquemático del flujo de datos dentro de un sistema genérico de clonación de voz.
Figura 2: Resumen esquemático del flujo de datos dentro de un sistema genérico de clonación de voz.
Paso a paso
Para la implementación de coqui-ai TTS, se necesita instalar python >= 3.9, < 3.12. Aquí hay una guía sobre cómo instalar python, VSCode y conda.
Step 1: configuración del entorno
Ve a VSCode y abre un nuevo terminal. En ese terminal:
conda create --name coquisTTS python=3.9
conda activate coquisTTS
pip install ipykernel
pip install TTS
Step 2: Graba tus propios audios y elige el texto
En nuestro caso, utilizaremos tres archivos de audio de 5 a 10 segundos que Nerea nos ha enviado gustosamente para utilizarlos como muestras de su voz. El codificador de locutores los utilizará para condicionar la voz generada al estilo de Nerea.
Además, necesitaremos establecer lo que queremos que Nerea diga. Llevo años intentando leer "El Señor de los Anillos", pero nunca encuentro el momento. Esta es nuestra oportunidad: Nerea nos lo leerá en voz alta.
 Figura 3: una foto de Nerea compartiendo unas risas con el reparto de El Señor de los Anillos.
Figura 3: una foto de Nerea compartiendo unas risas con el reparto de El Señor de los Anillos.
Español:
Cuando el señor Bilbo Bolsón de Bolsón Cerrado anunció que muy pronto celebraría su cumpleaños centésimo decimoprimero con una fiesta de especial magnificencia, hubo muchos comentarios y excitación en Hobbiton.
Bilbo era muy rico y muy peculiar y había sido el asombro de la Comarca durante sesenta años, desde su memorable desaparición e inesperado regreso. Las riquezas que había traído de aquellos viajes se habían convertido en leyenda local y era creencia común, contra todo lo que pudieran decir los viejos, que en la colina de Bolsón Cerrado había muchos túneles atiborrados de tesoros. Como si esto no fuera suficiente para darle fama, el prolongado vigor del señor Bolsón era la maravilla de la Comarca. El tiempo pasaba, pero parecía afectarlo muy poco.
Inglés:
When Mr. Bilbo Baggins of Bag End announced that he would shortly be celebrating his eleventy-first birthday with a party of special magnificence, there was much talk and excitement in Hobbiton.
Bilbo was very rich and very peculiar, and had been the wonder of the Shire for sixty years, ever since his remarkable disappearance and unexpected return. The riches he had brought back from his travels had now become a local legend, and it was popularly believed, whatever the old folk might say, that the Hill at Bag End was full of tunnels stuffed with treasure. And if that was not enough for fame, there was also his prolonged vigour to marvel at. Time wore on, but it seemed to have little effect on Mr. Baggins.
Step 3: Escribiendo el código en python
Crea un cuaderno python (por ejemplo: test.ipynb) y dentro de una celda, ejecuta:
from TTS.api import TTS
import torch
#Get device
device="cuda:0" if torch.cuda.is_available() else "cpu"
SAMPLE_AUDIOS = ["sample1.mp3", "sample2.mp3", "sample3.mp3", "sample4.mp3", "sample5.mp3"]
OUTPUT_PATH = "LOTR.wav"
TEXT = "Write here the text we want Nerea to read."
#Init TTS with the target model name
tts = TTS(model_name="tts_models/multilingual/multi-dataset/xtts_v2", progress_bar=False).to(device)
#Run TTS
tts.tts_to_file(TEXT,
speaker_wav=SAMPLE_AUDIOS,
language="en", # "es" if the text is in spanish
file_path=OUTPUT_PATH,
split_sentences=True
)
#Listen to the generated audio
import IPython
IPython.display.Audio(OUTPUT_PATH)
Resultados
Audio generado en español:
Audio generado en inglés:
En mi opinión, se puede reconocer a Nerea hablando, pero con un ligero tono metálico, especialmente en el habla generada en lengua coss (el audio en inglés). En cuanto al audio podría faltar la naturalidad característica con la que Nerea siempre habla, pero considero que es un punto de partida prometedor que podría mejorarse afinando el modelo.
Dejemos que Nerea termine este artículo compartiendo algunas de sus ideas que su clon leyó en voz alta:
Si encuentras interesante este artículo, puedes seguirme en LinkedIN
Nuestras últimas novedades
¿Te interesa saber cómo nos adaptamos constantemente a la nueva frontera digital?

Tech Insight
1 de julio de 2026
La nueva era de la Programación Agéntica: Antigravity 2.0 y Sngular Gen

Tech Insight
25 de junio de 2026
Que lo haga Gemini: IA generativa para empresas en Google Cloud

Tech Insight
18 de junio de 2026
Sin datos no hay IA: Agentic Data Cloud y la soberanía de la información

Tech Insight
16 de junio de 2026
Generative UI: cuando la IA no solo responde, sino que construye la interfaz