
Contract Testing & CI

May 19, 2023
Here we are again, with the third release of the Road to PactFlow Enterprise series.
This time we will deal with an advanced topic: CI/CD implementation. But not just at a high level as we did in our first article “Contract Testing Workflows”, in this one we will go deeper and talk about very particular situations you are likely to face,and the options you have to deal with them.
We will try to give not only some of the solutions we have implemented for these situations, but also a bit of context about why we did it that way and why the situation happened. Following this format, we hope to make it friendly for anyone with basic knowledge about the Contract Testing framework and its integration in enterprise pipelines.
Of course, these are just examples, and there are many ways to face a configuration need. Each one would have its own advantages and disadvantages. The ones listed here aim to work as a showcase and hopefully guidance for someone in the same situation.
Webhooks auto-creation
Context
Webhooks are one of the most powerful components of PactFlow. They give us the power to integrate contract testing with our team workflows, orchestrate our pipelines and automate anything we want in response to a contract-related event. You can read more about webhooks in this article by Matt Fellows or in the official PactFlow documentation.
Situation
Ok, we love webhooks, but when implementing contract testing in a large-scale company we don’t want to create them manually. The PactFlow responsible team will have a lot of work related to platform, integration, and adoption to be overloaded as well with the manual creation of webhooks for each one of the applications (not teams!) that make use of the product.
One possible solution
Integrate the creation in your pipelines. Pretty obvious taking into account the title of the article, right? We have done this kind of adaptation in many of our clients, and the CI workflow use to look like this:
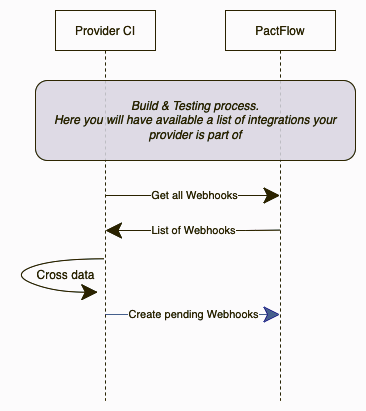
As you can see, webhook creation automation is included in the provider pipelines. First of all, we request to PactFlow all the existing webhooks configured for the provider and all the integrations. With that information, we can check if an integration (contract between consumer A and provider B) has a dedicated webhook triggering the verification pipeline from provider B. If that webhook does not exist, we can assume that it must be created.
If you’re using the Pact CLI instead of direct API calls, the process is much easier as you have the “create-or-update-webhook” available, so you will not need to worry about checking anything.
This approach consists of creating a dedicated webhook individually for each of the consumers, but you also have the option of not specifying the consumer. This way, any new consumer that joins will automatically be included in the webhook event.
By following this approach, the webhooks will be reviewed and created for each provider during each build. We only focus on the creation because PactFlow itself will handle the deletion of the webhooks if an integration is deleted.
This approach has a drawback, the very first execution of a consumer publishing a new contract integration will fail as there will not be any webhook to trigger the verification until the provider does a build. We would love to be able to automate the webhooks creations in the consumer build, but depending on the client infrastructure, it may be not possible to determine the provider Jenkins URL from a consumer build execution. Actually, this is the most common situation we have found so far.
Alternatives
The most obvious alternative is to create them manually, even though we don’t recommend that at all in big organizations.
Another alternative could be to isolate the webhook creation in a dedicated job, giving you more control over when the creation is executed. You can schedule the execution of that process as part of your application onboarding.
Honestly, none of them sound convincing to us. We’re pretty fans of automating the process all the possible.
But, if your organization has access to tools like Terraform you should be able to automate the provider, webhooks, or team onboarding. Check this Terraform Provider Pact repository.
Wait for it… can-i-deploy
Context
If you still don’t know what can-i-deploy is, you can read this Pactflow official post that summarizes pretty well what is the purpose of this core contract testing operation
In introductory contents, we used to see the typical diagrams where the consumer pipeline just waits for the PactFlow webhook callback to continue with the can-i-deploy (waiting for the provider verification to happen). You can see an example of what we’re talking about in the First Execution - Consumer Driven section of ourContract Testing Workflows article.
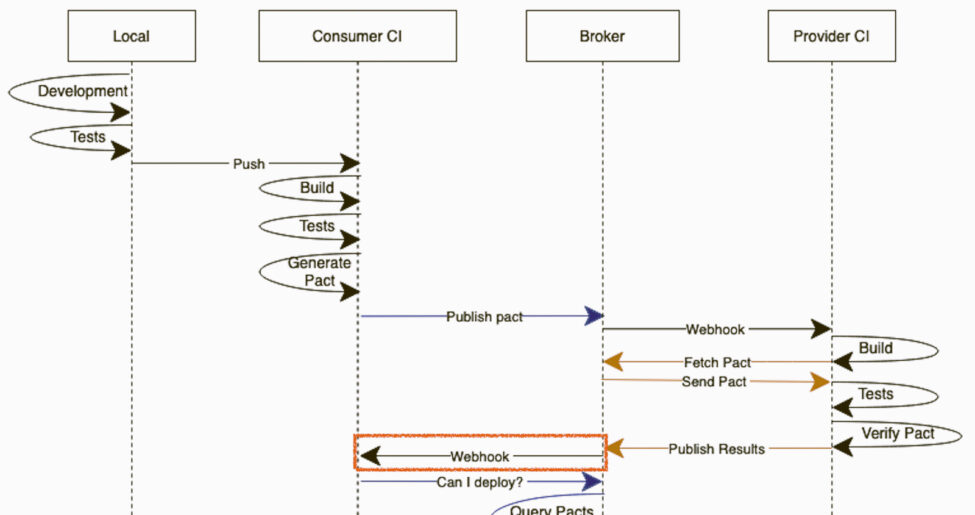
Although this is a really useful representation to understand the concept in training sessions, in a real-world scenario where you’re implementing cooperative pipelines used by tons of applications… it could be pretty controversial. The CI/CD responsible team is not going to like at all to have a pipeline frozen waiting for a webhook callback that even may not happen.
One possible solution
We like to make our can-i-deploy independent for any callback. This has two advantages: the consumer pipeline is self-sufficient handling its own process, and you save the creation of one webhook per integration (oh, and your CI/CD responsible team will be much more relaxed 😅*)*
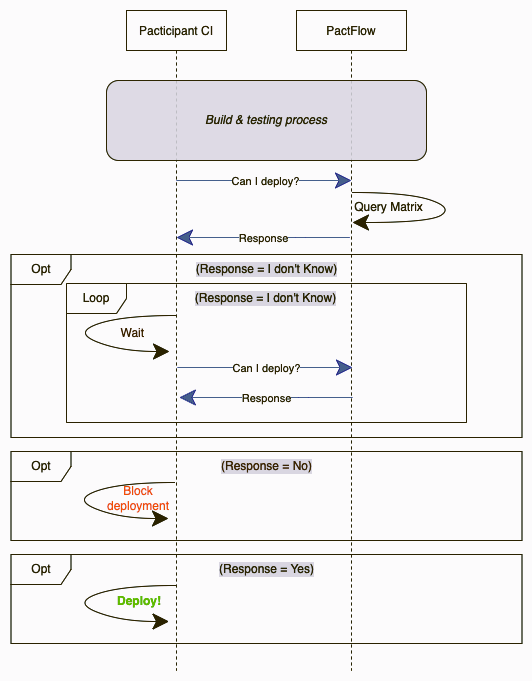
Basically, we’re repeating the can-i-deploy request a given number of times and increasing the wait in each iteration a bit (exponential backoff strategy). This call will be repeated only if the response from PactFlow is that no verification has been published. Once we have a verification failed or verification succeed, we will continue with the execution. Of course, it will have a limit of retries to avoid getting stuck.
The difference is subtle but important, the pipeline is not waiting for a callback call but is itself managing its own flow. It could be argued that it increases the network load unnecessarily, but we have generally found that the teams responsible for CI/CD like this approach better. So yeah, take this as an alternative to the classic approach.
Alternative
The Pact CLI offers with the can-i-deploy the possibility of using two parameters to configure this behavior:
- [--retry-while-unknown=TIMES]
- [--retry-interval=SECONDS]
It simplifies a lot of the implementation, but you would be missing the exponential backoff.
Verification dedicated pipeline
Context
Usually, when talking about the CI/CD, we tend to show examples of the verification process by using the full provider pipeline. Again, this is done to make the concept easier to understand, but in a real-world scenario, we will (probably) face a very different situation. It’s pretty common to find in our cooperative pipelines several steps that we may not want to execute when validating a consumer contract… like the packaging of the product, the upload to the artifactory, or even notification to management or workflow tools.
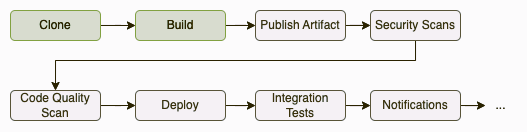
The point is that you will probably want to avoid this kind of step. All you’re looking for is to validate your contracts, but there’s no need every time to generate a new artifact or release or notify the teams about this validation.
One possible solution
The solution we tend to implement is to create a dedicated simplified pipeline for contract verification. This option simplifies a lot of all the process, at the end all we need from a contract testing perspective is to build and publish the verification. This approach will save time, and resources, but also simplify the final solution and give clear visibility to the validations performed.
You may have an independent step for the verification publish, but keep in mind that from the provider side if you want to validate the contract using the code it must be done by using the Pact dedicated plugin. If you want to use the Pact CLI to publish a verification, you would need to have an up & running provider version of the code. We find the plugin & code validation approach much more convenient.
These verification pipelines should work in concert with the webhooks (usually associated with the “contract requiring verification published” event). They should verify the specific pact passed in by the webhook, and not every deployed component as in the regular provider pipelines. We will go deeper into this concept in the next section of the article “Verification pipeline consumer selector strategy”.
Alternatives
There’s a clear alternative that is usually suggested by our clients: to make those steps optional by using conditional statements. Although is a very valid option, we prefer to opt for the isolated verification pipeline approach based on the advantages listed in the previous point.
Verification pipeline consumer selector strategy
Context
As a quick definition, the consumer version selectors are a bunch of parameters, available in multiple languages and plugins, that allows you to filter the consumer contracts that are going to be downloaded & validated by a provider. In our opinion, this is a topic not deeply covered in technical articles, and it can become a headache if not understood and set up properly in your pipelines. You can find a lot of information related to the PacFlow official documentation, even related directly to your favorite plugins (like the Junit5 for example).
Just to make it a little more complex, imagine that we are working in an enterprise environment that has a dedicated pipeline for deployments. Meaning that the build and creation of a release candidate is done in a different pipeline than the deployment itself. It’s a pretty common situation in large companies, although in the demos we handle everything in just one pipeline thread. Being able to generate a repeatable version number is pretty important to make our lives easier, tools like this NPM package can be super helpful.
One possible solution
Depending on how you have configured your CI/CD, you will need to filter the contracts in one way or another. If you have a solution similar to what we have defined in this article until now (with a dedicated verification pipeline isolated from the common build) the most simple way to do it is to apply the following criteria:

To accomplish that, we can make use of the properties: deployed, latest & branch.
All of them are pretty self-explanatory, just keep in mind that the way to use them will depend on the code or plugin used for your validation. Some languages may have it included to be used in a specific way, some others may not. The good news is that all of them should at least support the raw JSON version selectors. An example using the Junit5 plugin with raw JSON selectors:


But, why this setup? Let’s explain in detail the configuration selected.
Why do we need to validate all the deployed contracts in our common build?
If you recall, we are building an isolated pipeline that is not going to be the one deploying. For that reason, we would need to perform the validation of every deployed contract, to have all the cases covered.
And why the “latest” published?
This is a tricky one! Imagine your first iteration. Your consumer publishes a contract, but it cannot deploy (as there is no provider available yet). You build your provider, and if you just validate the deployed contracts… this new contract will not be validated ever. That’s why you need to validate as well all the latest versions of each contract, to give coverage to this very specific situation.
But what happens if the consumer creates a new contract between my provider build and the deployment?
That’s precisely the reason why you have a PactFlow webhook configured to trigger your verification pipeline. The webhook will provide the branch from the consumer that has created the event (contract published that requires verification) and the pipeline will build & perform the verification using the related provider code. Remember that the webhook will trigger the verification of each one of the providers related. Meaning that if the new version is for a contract present in DEV, NON-PROD, and PROD it will trigger three verification runs (one per each provider version related).
The verification pipeline is much more precise than the regular build, it will verify just the required contracts.
Alternatives
There are quite a lot of alternatives. You can mix and combine different pipeline setups and a lot of different parameters for consumer version selection. It would be impossible to cover all the casuistic. With this section, we just wanted to draw your attention to these important parameters and the importance of their correct design.
Pacticipants verification
Context
As you may know, a pacticipant is a party that participates in a contract (ie. a consumer or a provider). With that in mind, you may also know that the pacticipant id is defined in code while developing the tests themselves. For example:
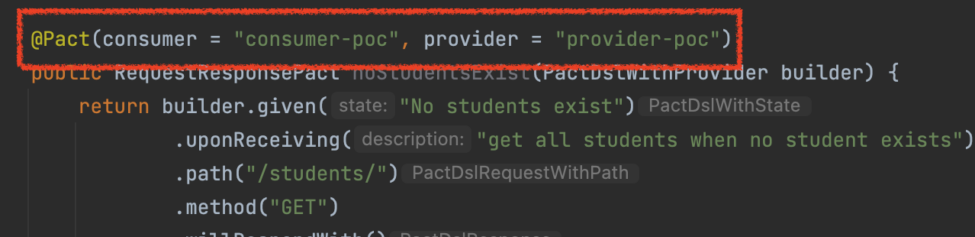
On another hand, we have people that work in platform management and toolchain. The kind of people that hates leaving core configurations open to the developers. I’m pretty sure you can see where this is taking us, right?
One very common request is to filter out any contract that is not related to an accepted pacticipant id. Although this is pretty complicated to achieve with 100% certainty, there are some easy tricks you can do to improve the validation of these ids.
If you want to validate the participant id, it means that you must have the value available somewhere. It may be a configuration file in the project, or maybe a file in a different infrastructure repository, or even in a database. It does not matter how, but you need to have a way to identify the expected participant id.
One possible solution
With the given context, the last important point to have in mind is that the contracts generated in a consumer are available in the build directory as a file, and they always have the following name convention:

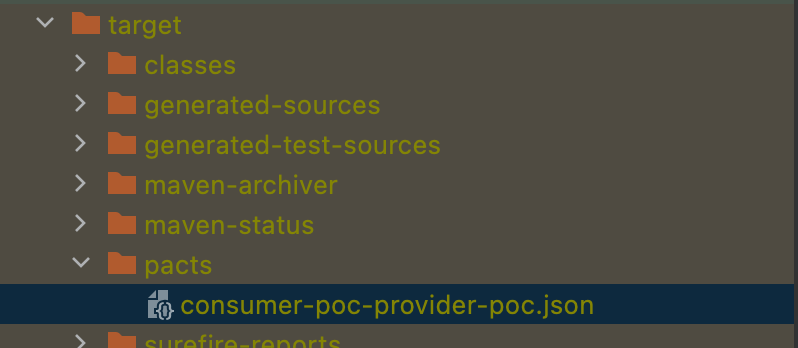
Based on our previous example, the consumer pacticipant ID would be consumer-poc, and the provider pacticipant ID would be provider-poc.
With these conditions, one thing we like to do in our consumer pipelines is to validate that the consumer is only publishing contracts related to itself. We can get the valid ID from the file/infra repository/database and then validate that the generated contracts start with the expected ID value. Having this in our pipelines will ensure that, at least, a consumer is not publishing a contract not related to itself.
As you can imagine, there is no easy way to validate the provider ID without coupling A LOT the two code repositories. That’s why we use to decide to assume that risk. If a consumer creates a contract with a non-existent provider ID, it will not have ever a related webhook (as its creation would be automated as explained in the Webhooks Auto-creation section). It would be just an orphan contract in PactFlow, and we can have periodic jobs to clean up contracts that have not been validated ever.
Alternatives
Personally I cannot imagine a good alternative for this situation, it’s a pretty specific feature with very specific objectives and I think this is the only way to do it. Probably is something that the PactFlow team has thought about much more than we have, and if there’s no out-of-the-box option to perform this kind of validation is probably because… is not possible. (or at least does not worth the effort). But on the other hand, we have heard this request more than once from our clients, so we thought it would be useful to share it.
Cross environment support
Context
When you’re working in a POC, or in your first tests, it’s pretty common to think in the environments like isolated regions. Your DEV deployment should be validated against the services deployed in DEV, right?
In our experience, this is not so easy in the real world. How many times have you deployed in your DEV environment pointing to a service deployed in (for example) UAT? It makes sense because the provider belongs to a different team. And that team will be maintaining and developing their own applications, so their DEV will not be stable precisely. And to avoid disruptions and problems during your development, they propose you use a higher environment.
But there’s more, maybe you’re consuming 3 services. One in DEV, the second one in UAT, and the third in SIT. Everything starts to get a bit complicated.
If we have to standardize and implement contract testing in a large organization, it is a situation we will almost certainly face.
One possible solution
The solution comes when you realize you can manipulate the verifications done by the can-i-deploy. That is the main trick.
The only requirement for the proposed solution would be to have available the integrations in the consumer code. It could be a configuration file or any other source. But you should be aware of the environment you’re using in your deployment and the participant ID of the services you integrate with. Usually is something easy to extract based on a naming convention, at the end, the consumer service should know where it’s pointing to in its requests. Once we have that identified, we will make use of the can-i-deploy ignore option.
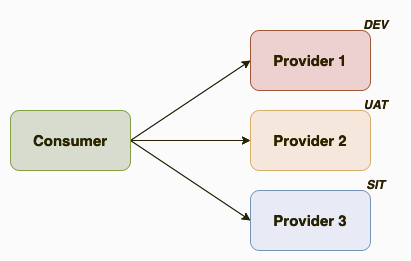
So, let's suppose we have the situation shown in the previous picture. For our deployment, we would need to execute 3 can-i-deploy functions. Only if the three executions are ok we will be safe to deploy.



Alternatives
If there is any alternative for this situation, please share that with us. We would love to know about other ways to handle this situation. As of now, this is the easiest and most efficient way we have identified.
The con this solution has is that this kind of validation use to be impossible to apply on the provider side. The provider does not use to know about their consumers, so in that case, we rely on the classic method of validating just the environment you’re going to be deployed on. We should keep in mind that this kind of deployment style use to happen just in the lower environments.
Extra (working on it…)
If you have enjoyed the Cross Environment Support… you will love this one: MultiEnvironment Support.
I will not detail a solution, as it is something we’re currently working on, but let me simply state the problem: The users can create different instances of an environment.
They can not only cross environments, but also generate additional environment instances at their sole discretion. Meaning that you will need to give coverage to DEV, DEV01, DEV02… until DEVXX for all of your environments.
This situation is not as crazy as it sounds, it’s a pretty useful feature for the development teams if you think about it. And many cloud platforms provide this capability by allowing easy namespace creation, or even on-demand creation of the environments.
We will share our thoughts the day we get to a common shareable pattern for this situation. If you have faced this already, please share your knowledge! We would love to chat with you.
Conclusion
We really hope you have enjoyed this article as much as we did writing it. Making a collection of many of the “special” situations we have faced automating contract testing has been funny and challenging at the same time. Hopefully, the concepts we have tried to share have been described clearly.
As always, I would like to end the article by recalling you that this is an entry part of the series: Road to PactFlow Enterprise. We will continue to add content related to this product we enjoy so much, so stay tuned and keep an eye out!